Em nosso dia a dia de trabalho nos deparamos com todos os tipos de dados, e em muitas situações estes não estão padronizados e encontram-se com erros ou variações de digitação, como por exemplo, as várias formas de se escrever Avenida (Av., Ave., Aven. Etc).
Para realizar este tipo de relacionamento ou padronização, podemos utilizar a ferramenta de Fuzzy Match e um pouco de conhecimento dos dados.
A ferramenta Fuzzy Match possui 2 âncoras:
- Âncora de entrada: Por mais que a ferramenta de fuzzy match realize comparações entre os dados para padronizar informações, ela apresenta apenas uma entrada de dados, onde toda a nossa base de dados será inserida. Em algumas situações será necessário realizar um passo anterior de identificação dos dados que será demonstrado nos exemplos abaixo
- Âncora de saída: a âncora de saída exibe os resultados da ferramenta Fuzzy Match.
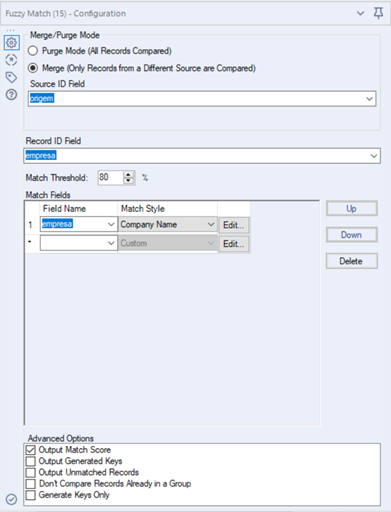
Existem 2 configurações principais de modo na ferramenta: Merge ou Purge
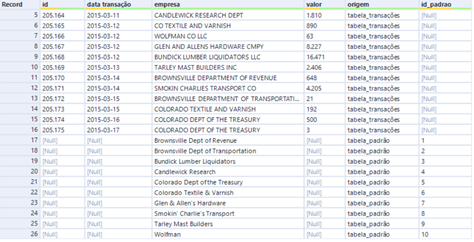
Para nosso exemplo, dê uma olhada nos dados abaixo:
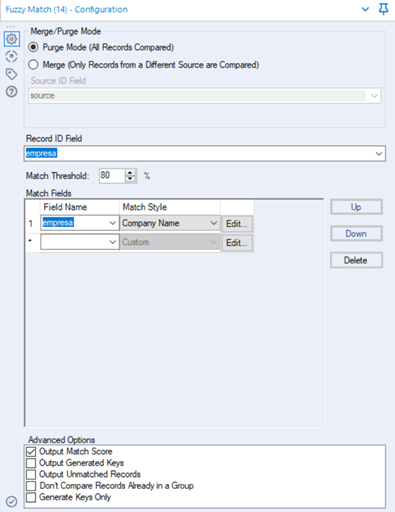
- Caso exista a necessidade, podemos criar a configuração avançada e criar um “match style” personalizado clicando em “Edit…”
4. Advanced Options: As opções avançadas nos permitem determinar o que será exibido na saída da ferramenta
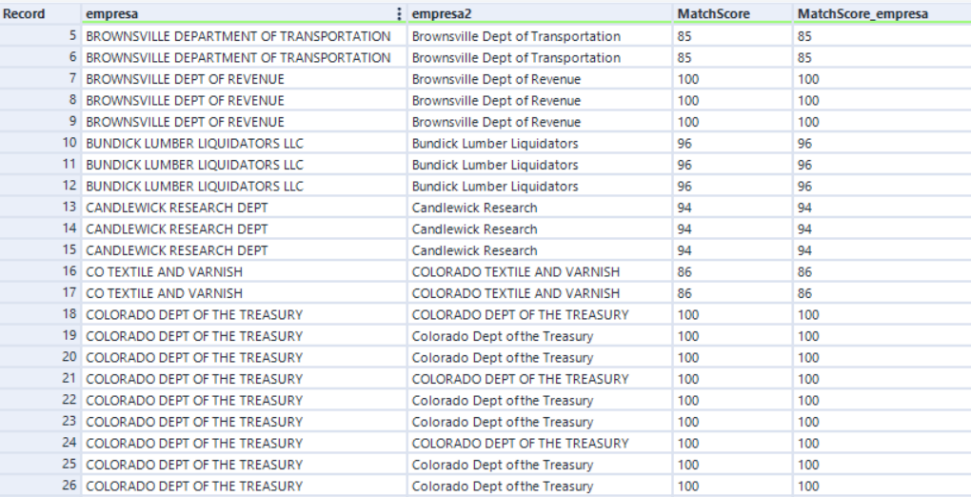
- Output Match Score: Gera uma coluna de assertividade para cada comparação entre os nomes, como demonstrado no item 2 acima;
- Output Generated Keys: Gera uma coluna com a chave de agrupamento. Por exemplo, as empresas WOLFMAN CO, WOLFMAN CO LLC, THE WOLFMAN CMPY possuirão uma mesma key, pois de acordo com a ferramenta elas são a mesma;
- Output Unmatched Records: Permite exibir também na saída de dados as empresas que não possuem necessidade de padronização;
- Don’t Compare Records Already in a Group: empresas que já foram alocadas em um relacionamento, não poderão ser utilizadas novamente para uma nova comparação;
- Generate Keys Only: Mantem como saída dos dados apenas as chaves de relacionamento
Com as configurações utilizadas anteriormente, iremos gerar o seguinte resultado:
MODO 2: MERGE MODE
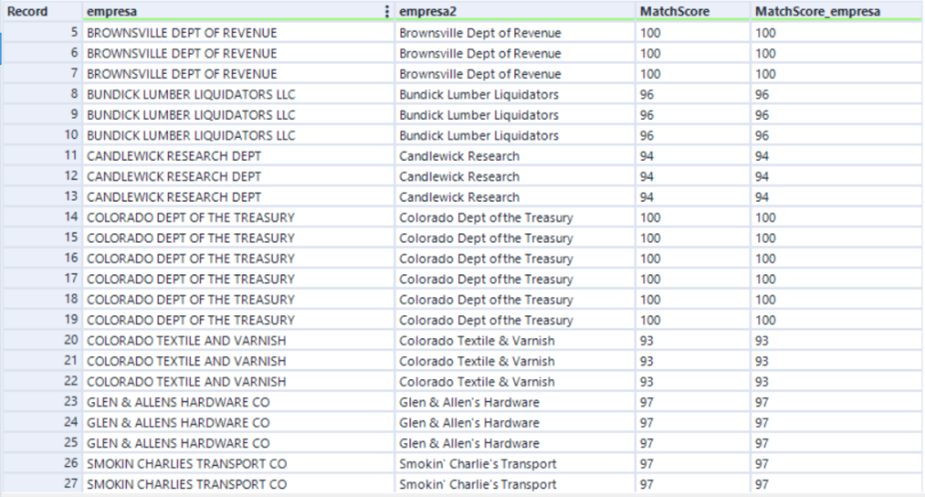
O modo merge irá possuir as mesmas configurações do modo purge, mas possui o diferencial de realizar a compração de fuzzy entre 2 grupos, aquele a ser padronizado e aquele que é o nosso padrão de dados.
Ao observarmos nossa base de dados original, vemos que existe a coluna chamada “origem”, onde identificamos 2 possibilidades: tabela_transações e tabela_padrão.
Através do modo purge iremos padronizar todas as linhas da “tabela_transações” com base nas informações presentes nas linhas de “tabela_padrão”, para isso Podemos utilizar a seguinte configuração:
Podemos observar que o modo Merge apresenta uma consistência maior nos dados, mas só é possível utilizá-lo se tivermos a forma correta que desejamos alcançar. Caso esse padrão não exista, o caminho é utilizar o modo Purge, onde o Alteryx irá utilizar a própria base para comparação.