Nesta dica, vamos entender como realizar a leitura de PDF utilizando Alteryx.
INTRODUÇÃO
Para aqueles que nos acompanham a mais tempo, devem estar se perguntar “Mas vocês já não falaram disso antes?”. E para vocês caros espectadores atentos, a resposta é “sim”, já falamos sobre leitura de PDF mais de uma vez.
A primeira vez que falamos sobre ela foi na dica “ANALISANDO DOCUMENTOS COM PDF INPUT” (hyperlink) em 2020. E novamente falamos sobre leitura de PDF na dica “COMO UTILIZAR A FERRAMENTA IMAGE INPUT PARA INTERPRETAR IMAGENS PNG, JPEG, BMP OU PDF” (hyperlink) em 2021.
E com essas dicas percebemos o quanto o Alteryx vem melhorando sua habilidade de ler arquivos em PDF. Agora trazemos para vocês a mais nova ferramenta do pacote Intelligence Suite, a ferramenta de PDF para Texto (PDF to Text).
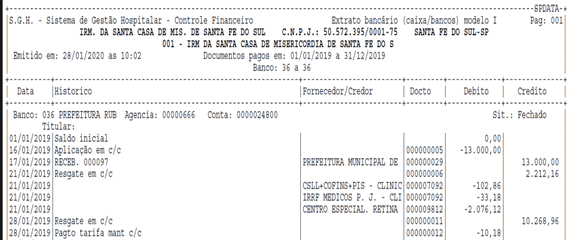
Para essa dica utilizaremos um extrato bancário com movimentações fictícias.
PASSO 01: ENTENDENDO AS ENTRADAS E SAÍDAS DA FERRAMENTA
A ferramenta de “PDF para Texto”, possui 2 entradas. A entrada “D” (entrada de Dados), e a entrada “T” (Template), ambas são opcionais.
A Entrada de Dados requer o caminho para o arquivo PDF, então podemos utilizar a configuração da própria ferramenta para determinar um arquivo específico, ou podemos utilizar a entrada “D” para conectarmos por exemplo a uma ferramenta de Diretório.
Já a entrada de Template requer um exemplo de conteúdo do PDF, e a ferramenta mais recomendada para essa conexão é a “Modelo de Imagem”.
PASSO 01: ENTENDENDO AS ENTRADAS E SAÍDAS DA FERRAMENTA
Quando pensamos em leitura de PDF já pensamos em complexidade de leitura e erros de conversão, e nesse caso, a ferramenta de PDF para Texto resolve os 2 problemas com uma configuração simples e intuitiva e resultados impressionantes.
Vamos primeiramente entender as configurações:
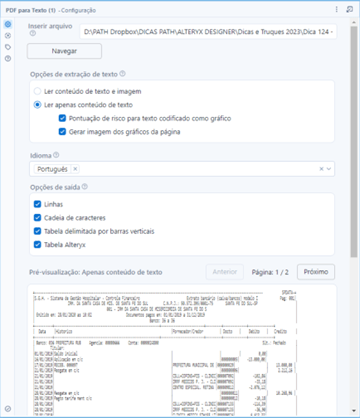
Inserir Arquivo
Na parte superior iremos selecionar o caminho para o arquivo PDF que queremos ler. Caso exista uma conexão na entrada “D”, iremos apenas selecionar qual coluna da nossa base de dados contem o caminho para o arquivo PDF.
Opções de extração de texto
Nesta configuração iremos selecionar qual tipo de leitura será realizada, se selecionarmos a opção “Ler Conteúdo de Texto e imagem” o Alteryx irá interpretar de forma dinâmica textos e imagens utilizando OCR, sendo essa forma mais fácil deixando a inteligência do Alteryx decidir, mas pode ser mais custosa do que precisaria ser.
Selecionando a opção “Ler apenas conteúdo de Texto”, será feita a interpretação dos caracteres sem a utilização de OCR, sendo essa forma até 10x mais rápida que a anterior, mas com isso vem algumas configurações a mais como “pontuação de risco” e “gerar imagens dos gráficos”.
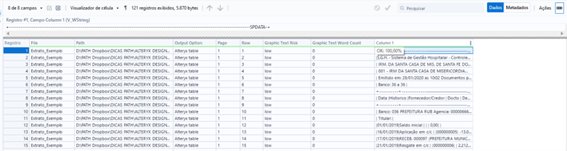
A Pontuação de Risco nos permite analisar a precisão da interpretação do PDF, linhas com risco baixo (low), estão em bom estado para serem utilizadas. Linhas com risco médio ou alto (medium / High), devem passar por um tratamento na ferramenta Image Tool com utilização de OCR.
Idioma
Aqui determinamos qual ou quais idiomas compõe o conteúdo do arquivo PDF ( E SIM, TEMOS PORTUGUÊS )
Opções de Saída
Nas opções de saída determinamos qual conteúdo é importante após toda a análise configurada anteriormente.
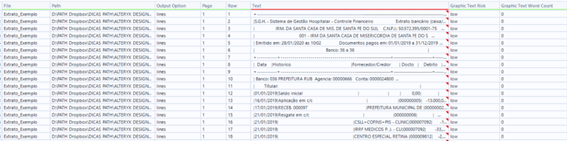
Linhas – Separação em cada linha por linha da página, mantendo seu formato padrão com múltiplos espaços e separações de conteúdo
Cadeia de Caracteres – Separação por página, mantendo uma linha única com todos os dados para cada página
Tabela Delimitada por Barras Verticais – Separação por página, mantendo uma linha com todos os registros das páginas, mas com a separação de barra para cada quebra de linha
Tabela Alteryx – Separação Linha por Linha, mas com uma certa limpeza de dados, removendo espaços duplicados e espaços desnecessário
5. Pré-visualização
Nessa parte é possível ver como está o conteúdo do arquivo PDF lido.
ATENÇÃO: Também podemos utilizar o wildcard (*) na configuração do caminho, mas nesse caso não teremos a pré-visualização dos dados.
19 de janeiro de 2022
Pronto! Agora você já sabe os usos da mais nova ferramenta PDF para Texto.